使用open-falcon cAdvisor实现对k8s(kubernetes)集群的监控
1. 前言
当我们的k8s要面临落地时,监控和日志肯定时不可缺少的。它主要为了帮助系统运维人员事前及时预警发现故障,事后通过翔实的数据追查定位问题。
2. 可选方案
- Heapster(数据采集自cAdvisor)+Influxdb(存储)+Grafana(展示)
这套方案缺点是没有报警功能 -
Prometheus+Grafana
参考:http://blog.csdn.net/zqg5258423/article/details/53119009 -
open-falcon+cAdvisor
本文主要介绍这种方式,官方文档:https://book.open-falcon.org/zh/intro/index.html
实际案例:https://zhuanlan.zhihu.com/p/27697789
3. openfalcon架构图
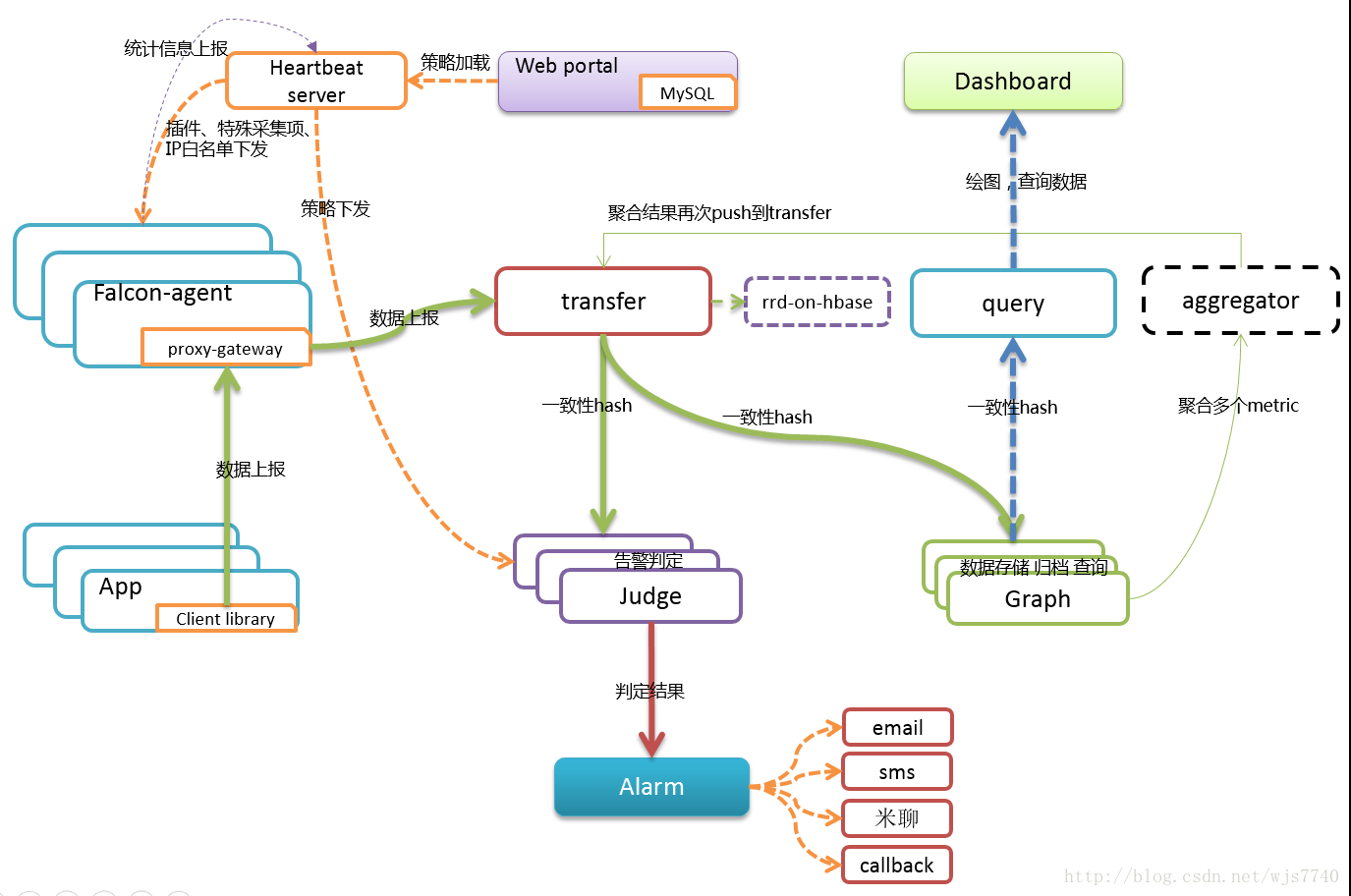
可以看到,它的核心组件是agent,它需要运行在每台node上获取数据,所以对于k8s集群的监控,我们会主要对agent做二次开发,嵌入cAdvisor代码,实现对容器的监控。
4. 涉及的组件及简要说明
- agent 监控信息上报 需要二次开发
- transfer 监控信息转发
- graph 监控信息存储
- query 监控信息查询
- hbs 心跳服务器
- judge 报警事件判断
- alarm 报警事件处理 需要二次开发
- sender 报警事件发送 需要二次开发
- nodata 假数据填充
- Redis 报警事件队列
5. 监控流程
Agent监控各个主机和容器的信息(嵌入了cadvisor代码),并将数据通过transfer转发存入graph,控制台通过http方式访问query api查询graph获取数据。
6. 报警流程
不再单独部署portal模块,报警策略信息由控制台报警模块提供并写入MySQL的portal数据库,供hbs读取,hbs加载mysql portal库策略数据并关联到endpoint后提供给Judge组件使用,transfer转发到judge的每一条数据会触发相关策略进行判断将结果放入redis,alarm从redis中获取报警event后保存至控制台数据库,以提供控制台
前端展示报警信息
7. 监控系统本身的健康检查
对于k8s集群主机的基础指标监控,容器的基本指标,我们用falcon来监控, 而k8s核心组件和falcon核心组件的可用性监控,用一个独立的工具scripts来监控,它会部署在多个数据中心的多台主机上进行探测。
对监控系统的监控不能再依赖于监控系统, 使用独立工具的好处在于没有依赖,简单稳定,可用性高。而多中心多主机的部署也是为了保证工具的可用性。
标签云
-
DeepinUbuntuPostfixLUA集群AppleSystemd部署KloxoFlutterCDNTensorFlow缓存Tomcat代理服务器LighttpdSecureCRTVsftpdWgetOpenVZOfficeFirewalldTcpdumpiPhonePostgreSQLNginxKubernetesCrontabKVMBashGoogleSwarmAndroidGolang备份VirtualminNFSSSHSocketKotlinAnsibleMacOSPHPSwiftDockerVirtualboxSaltStackIOSSambaRedisWPS容器RedhatPythonVagrantMySQLApacheMariaDBSVNHAproxyRsyncCentosSQLAlchemyWordPressJenkinsShellWindowsSnmpLinuxMemcacheInnoDBCactiFlaskSupervisorMongodbVPSsquidOpenresty监控IptablesDNSOpenStackWiresharkCurlLVMPuttyGITYumZabbixDebian