Redis笔记(三)Redis持久化
持久化的作用
么是持久化
Redis的数据操作都在内存中,redis崩掉的话,会丢失。Redis持久化就是对数据的更新异步的保存在磁盘上,以便数据恢复。
持久化的实现方式
- 快照方式
对数据在某时某点的一种完整备份。例如Redis RDB,MySQL Dump都是这种方式。 -
写日志方式
任何数据的更新都记录在日志当中,某个时候要进行数据的恢复时,重走一遍日志的完整过程。例如MySQL的Binlog,HBase的HLog和Redis的AOF,就是这种方式。
RDB
什么是RDB
将Redis内存中的数据,完整的生成一个快照,以二进制格式文件(后缀RDB)保存在硬盘当中。当需要进行恢复时,再从硬盘加载到内存中。
Redis主从复制,用的也是基于RDB方式,做一个复制文件的传输。
三种触发方式
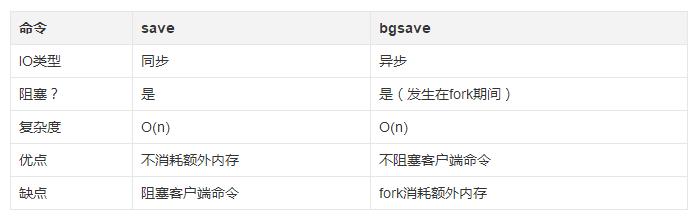
- save命令触发方式(同步)
redis> save
OK
save执行时,会造成Redis的阻塞。所有数据操作命令都要排队等待它完成。
文件策略:新生成一个新的临时文件,当save执行完后,用新的替换老的。
- bgsave命令触发方式(异步)
redis> bgsave
Background saving started
客户端对Redis服务器下达bgsave命令时,Redis会fork出一个子进程进行RDB文件的生成。当RDB生成完毕后,子进程再反馈给主进程。fork子进程时也会阻塞,不过正常情况下fork过程都非常快的。
文件策略:与save命令相同。
save与bgsave对比:
- 规则自动触发方式
某些条件达到时,自动生成RDB文件。
比如我们配置如下:
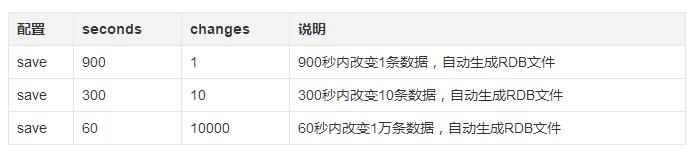
以上任一条件达到时,都会触发生成RDB文件。不过这种方式对RDB文件的生成频率不太好控制。如果写量大,RDB生成会很频繁。不是一种好的方式。
修改配置文件:
# 配置自动生成规则。一般不建议配置自动生成RDB文件
save 900 1
save 300 10
save 60 10000
# 指定rdb文件名
dbfilename dump-${port}.rdb
# 指定rdb文件目录
dir /opt/redis/data
# bgsave发生错误,停止写入
stop-writes-on-bgsave-error yes
# rdb文件采用压缩格式
rdbcompression yes
# 对rdb文件进行校验
rdbchecksum yes
不容忽略的触发方式
- 全量复制
主从复制时,主会自动生成RDB文件。 -
debug reload
Redis中的debug reload提供debug级别的重启,不清空内存的一种重启,这种方式也会触发RDB文件的生成。 -
shutdown
会触发RDB文件的生成。
试验
save试验
cd redis
cd config
cp ../redis.conf
cp redis.conf redis-6379.conf
vim redis-6379.conf
修改如下配置:
daemonize yes
pidfile /var/run/redis-6379.pid
port 6379
logfile "6379.log"
# 先关闭自动生成RDB的配置
# save 900 1
# save 300 10
# save 60 10000
stop-writes-on-bgsave-error yes
rdbcompression yes
rdbchecksum yes
dbfilename dump-6379.rdb
dir /opt/soft/redis/data
保存配置
:wq
# 重启redis
redis-server redis-6379.conf
# 客户端连接
redis-cli
# 暂时还没有Redis内存数据
127.0.0.1:6379> dbsize
(integer) 0
然后写个简单for循环程序,往Redis执行大量的写命令,让内存数据足够大。
# 再看一下,这下内存数据有很多了
127.0.0.1:6379> dbsize
(integer) 5000000
# 看下内存使用了904M,足够用以演示save的阻塞了
127.0.0.1:6379> info memory
used_memory: 948306016
used_memory_human: 904.38M
used_memory_rss: 1031897088
used_memory_peak: 981827104
used_memory_peak_human: 936.34M
used_memory_lua: 36864
mem_fragmentation_ratio: 1.09
mem_allocator: libc
# 执行save,发现等待了若干秒后,才输出OK以及消耗时间
127.0.0.1:6379> save
OK
(8.94s)
/opt/soft/redis/data目录下也会生成dump-6379.rdb文件。
bgsave试验
验证bgsave的非阻塞:
# 我们再开一个新窗口,在新窗口上连接redis客户端
redis-cli
# 输好以下命令,先别执行
127.0.0.1:6379> get hello
# 然后在原窗口执行bgsave
127.0.0.1:6379> bgsave
Background saving started
# 马上切回新窗口,回车执行命令,发现world即刻返回,验证了bgsave的非阻塞
127.0.0.1:6379> get hello
"world"
接下来验证bgsave会生成子进程:
# 在新窗口先查看下redis进程,过滤掉客户端和grep进程,发现就只有一个redis主进程
ps -ef | grep redis- | grep -v "redis-cli" | grep -v "grep"
501 36775 1 0 10:22下午 ?? 0:17 .86 redis-server *:6379
# 在原窗口再执行一次bgsave
127.0.0.1:6379> bgsave
Background saving started
# 马上切新窗口再次查看进程,发现多了个子进程redis-rdb-bgsave
ps -ef | grep redis- | grep -v "redis-cli" | grep -v "grep"
501 36775 1 0 10:22下午 ?? 0:17 .91 redis-server *:6379
501 36954 1 0 10:28下午 ?? 0:02 .81 redis-rdb-bgsave *:6379
# 再看一次,子进程已经不在了。因为子进程已经完成了它生成rdb文件的工作
ps -ef | grep redis- | grep -v "redis-cli" | grep -v "grep"
501 36775 1 0 10:22下午 ?? 0:17 .91 redis-server *:6379
最后验证文件策略:
# 在新窗口/data目录查看文件
ls
6379.log dump-6379.log
# 在原窗口再执行一次bgsave
127.0.0.1:6379> bgsave
Background saving started
# 切新窗口再次查看文件,多了个临时的rdb文件
ls
6379.log dump-6379.rdb temp-36985.rdb
# 过会儿再查看一次,临时文件消失了
ls
6379.log dump-6379.rdb
自动生成试验
这个不演示了,自己修改配置文件save 60 5,配置60秒更新5次就自动生成RDB文件。重启redis后,我们在客户端用set命令执行5次。观察/data下的rdb文件的时间戳是否变化了来验证。
我们也可以查看下日志文件6379.log,输出了试验过程的相关日志内容。
RDB总结
- RDB是Redis内存到硬盘的快照,用于持久化;
-
save通常会阻塞redis;
-
bgsave通常不会阻塞redis,但是会fork新进程;
-
save自动配置满足任一就会被执行;
-
有些触发机制不容忽视。
AOF
RDB存在的问题
-
耗时、耗内存、耗IO性能
将内存中的数据全部dump到硬盘当中,耗时。bgsave的方式fork()子进程耗额外内存。大量的硬盘读写耗费IO性能。 -
不可控、丢失数据
宕机时,上次快照之后写入的内存数据,将会丢失。
什么是AOF
就是写日志,每次执行Redis写命令,让命令同时记录日志(以AOF日志格式)。Redis宕机时,只要进行日志回放就可以恢复数据。
AOF三种策略
首先Redis执行写命令,将命令刷新到硬盘缓冲区当中。
- always
always策略让缓冲区中的数据即时刷新到硬盘。 -
everysec
everysec策略让缓冲区中的数据每秒刷新到硬盘。相比always,在高写入量的情况下,可以保护硬盘。出现故障可能会丢失一秒数据。 -
no
刷新策略让操作系统来决定。
三种策略对比
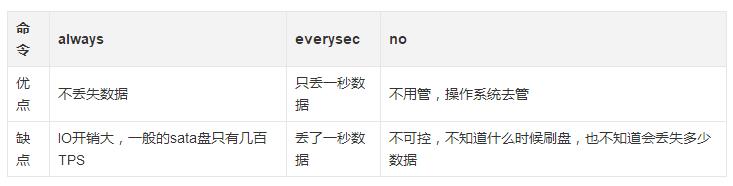
通常使用everysec策略,这也是AOF的默认策略。
AOF重写
随着时间的推移,命令的逐步写入。AOF文件也会逐渐变大。当我们用AOF来恢复时会很慢,而且当文件无限增大时,对硬盘的管理,对写入的速度也会有产生影响。Redis当然考虑到这个问题,所以就有了AOF重写。
原生AOF:
set hello world
set hello java
set hello python
incr counter
incr counter
rpush mylist a
rpush mylist b
rpush mylist c
过期数据
重写后的AOF:
set hello python
set incr 2
rpush mylist a b c
AOF重写就是把过期的、没用的、重复的以及可优化的命令,进行化简。只取最终有价值的结果。虽然写入操作很频繁,但系统定义的key的量是相对有限的。
AOF重写可以大大压缩最终日志文件的大小。从而减少磁盘占用量,加快数据恢复速度。比如我们有个计数的服务,有很多自增的操作,比如有一个key自增到1个亿,对AOF文件来说就是一亿次incr。AOF重写就只用记1条记录。
AOF重写两种方式
- bgrewriteaof命令触发AOF重写
redis客户端向Redis发bgrewriteaof命令,redis服务端fork一个子进程去完成AOF重写。这里的AOF重写,是将Redis内存中的数据进行一次回溯,回溯成AOF文件。而不是重写AOF文件生成新的AOF文件去替换。 -
AOF重写配置
auto-aof-rewrite-min-size:AOF文件重写需要的尺寸
auto-aof-rewrite-percentage:AOF文件增长率
redis提供了aof_current_size和aof_base_size,分别用来统计AOF当前尺寸(单位:字节)和AOF上次启动和重写的尺寸(单位:字节)。
AOF自动重写的触发时机,同时满足以下两点): - aof_current_size > auto-aof-rewrite-min-size
- aof_current_size – aof_base_size/aof_base_size > auto-aof-rewrite-percentage
AOF重写配置
修改配置文件:
# 开启正常AOF的append刷盘操作
appendonly yes
# AOF文件名
appendfilename "appendonly-6379.aof"
# 每秒刷盘
appendfsync everysec
# 文件目录
dir /opt/soft/redis/data
# AOF重写增长率
auto-aof-rewrite-percentage 100
# AOF重写最小尺寸
auto-aof-rewrite-min-size 64mb
# AOF重写期间是否暂停append操作。AOF重写非常消耗磁盘性能,而正常的AOF过程中也会往磁盘刷数据。
# 通常偏向考虑性能,设为yes。万一重写失败了,这期间正常AOF的数据会丢失,因为我们选择了重写期间放弃了正常AOF刷盘。
no-appendfsync-on-rewrite yes
试验
redis-cli
127.0.0.1:6379> dbsize
(integer) 5000000
127.0.0.1:6379> exit
vim redis-6379.conf
appendonly yes
appendfilename "appendonly.aof"
appendfsync everysec
no-appendfsync-on-rewrite yes
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
aof-load-truncated yes
配置修改后,要重新启动redis。
appendonly是支持动态配置,不用重启Redis:
127.0.0.1:6379> config get appendonly
1) "appendonly"
2) "no"
127.0.0.1:6379> config set appendonly yes
OK
# 重新加载配置
127.0.0.1:6379> config rewrite
OK
127.0.0.1:6379> exit
先试验下正常AOF刷盘
# 客户端连接redis,执行一些命令:
redis-cli
127.0.0.1:6379> set hello world
OK
127.0.0.1:6379> set hello java
OK
127.0.0.1:6379> set hello redis
OK
127.0.0.1:6379> incr counter
(integer) 1
127.0.0.1:6379> incr counter
(integer) 2
127.0.0.1:6379> rpush list a
(integer) 1
127.0.0.1:6379> rpush list b
(integer) 2
127.0.0.1:6379> rpush list c
(integer) 3
127.0.0.1:6379> exit
# 我们查看data目录,appendonly.aof文件已经生成了
cd /opt/soft/redis/data
ll
-rw-r--r-- 1 carlosfu staff 16K 10 7 22:28 6379.log
-rw-r--r-- 1 carlosfu staff 243B 10 7 22:29 appendonly.aof
-rw-r--r-- 1 carlosfu staff 18B 10 7 22:19 dump-6379.rdb
再试验下AOF重写
redis-cli
127.0.0.1:6379> bgrewriteaof
Background append only file rewriteing started
127.0.0.1:6379> dbsize
(integer) 3
# 我们再查看data目录,appendonly.aof文件变小了
cd /opt/soft/redis/data
ll
-rw-r--r-- 1 carlosfu staff 17K 10 7 22:33 6379.log
-rw-r--r-- 1 carlosfu staff 137B 10 7 22:33 appendonly.aof
-rw-r--r-- 1 carlosfu staff 18B 10 7 22:19 dump-6379.rdb
RDB和AOF的抉择
RDB和AOF的比较

RDB最佳策略
- 建议关闭RDB
无论是Redis主节点,还是从节点,都建议关掉RDB。但是关掉不是绝对的,主从复制时还是会借助RDB。 -
用作数据备份
RDB虽然是很重的操作,但是对数据备份很有作用。文件大小比较小,可以按天或按小时进行数据备份。 -
主从,从开?
在极个别的场景下,需要在从节点开RDB,可以再本地保存这样子的一个历史的RDB文件。虽然从节点不进行读写,但是Redis往往单机多部署,由于RDB是个很重的操作,所以还是会对CPU、硬盘和内存造成一定影响。根据实际需求进行设定。
AOF最佳策略
-
建议开启AOF
如果Redis数据只是用作数据源的缓存,并且缓存丢失后从数据源重新加载不会对数据源造成太大压力,这种情况下。AOF可以关。 -
AOF重写集中管理
单机多部署情况下,发生大量fork可能会内存爆满。 -
everysec
建议采用每秒刷盘策略
最佳策略
-
小分片
使用maxmemary对Redis最大内存进行规划。 -
缓存和存储
根据缓存和存储的特性来决定使用哪种策略 -
监控(硬盘、内存、负载、网络)
-
足够的内存
不要把就机器全部的内存规划给Redis。不然会出很多问题。像客户端缓冲区等,不受maxmemary限制。规划不当可能会产生SWAP、OOM等问题。
开发运维常见问题
fork操作
fork是一个同步操作。执行bgsave和bgrewriteaof时都会执行fork操作,
改善fork
- 优先使用物理机或者其他能高效支持form操作的虚拟化技术;
-
控制Redis实例最大可用内存maxmemary;
fork操作只是执行内存页的拷贝,大部分情况速度是比较快的。redis内存越大,内存页越大。可以使用maxmemary规划redis内存,避免fork过慢。 -
合理配置Linux内存分配策略:vm.overcommit_memory=1
fork时如果内存不够,会阻塞。Linux的vm.overcommit_memory默认为0,不会分配额外内存
子进程开销和优化
bgsave和bgrewriteaof会进行fork操作产生子进程。
- CPU
- 开销:RDB和AOF文件生成属于CPU密集型;
- 优化:不做CPU绑定,不和CPU密集型应用部署在一起;
- 内存
- 开销:fork内存开销
- 优化:echo never > /sys/kernel/mm/transparent_hugepage/enabled
- 硬盘
- 开销:AOF和RDB文件写入,可以结合iostat和iotao分析
- 优化:
- 不要和高硬盘负载服务部署在一起:存储服务、消息队列;
- no-appendfsync-on-rewrite=yes;
- 根据写入量决定磁盘类型:例如sdd;
- 单机多实例持久化文件目录可以考虑分盘;
AOF追加阻塞
AOF阻塞定位
redis日志:
Asynchronous AOF fsync is taking to long(disk is busy?). Writing the AOF
buffer whitout waiting for fsync to complete, this may slow down Redis
info persistence
可以查看上述日志发生的次数。
127.0.0.1:6379> info persistence
......
......
aof_delayed_fsync: 100
......
......
改善方式
同子进程的硬盘优化。
标签云
-
KubernetesVirtualboxOfficeSQLAlchemyRsyncHAproxy集群AnsibleGolangApacheRedhatSambaMongodbDebianMacOSSwiftOpenStackWgetFlutterBashWiresharkTensorFlow监控Jenkins代理服务器YumWordPressSSHNFSWPSVsftpdDeepinDockerFlaskiPhoneGITLVMSupervisorCactiSwarm备份IptablesOpenrestyLUAIOSPostfixWindowsDNSCentosFirewalld部署NginxZabbixSaltStackMemcachePythonInnoDBTcpdumpLighttpdShellMariaDBTomcatKVMKloxoAppleCrontabVPSKotlinGoogleSnmpCurlCDNPostgreSQLOpenVZRedissquidSecureCRTAndroidVirtualminPHPPuttySocketSystemdMySQL容器缓存SVNUbuntuLinuxVagrant