场景式解读 Git 工作流
很开心跟大家分享我自己对工作流的理解,包括我们公司自身正在进行的实践,还有 Coding 的一些用户提出的他们对于工作流的理解。
我希望在今天讲座之后在座的各位可以根据自身开发的具体工作内容,团队的规模和开发的形式,从我提出的几种工作流中找到自己合适的套路,也可以在自有的套路上扩展支撑自己公司特定的流程。
工作流
什么叫好的工作流呢?适合你的场景就是好,所以今天聊得是场景式解读工作流。工作流从字面意义上理解可以涵盖你工作的各个方面,包括任务管理产品最终上线的反馈,但是我们这边讲工作流只是用 Git 管理代码中,你与别人代码仓库如何协作的工作流。
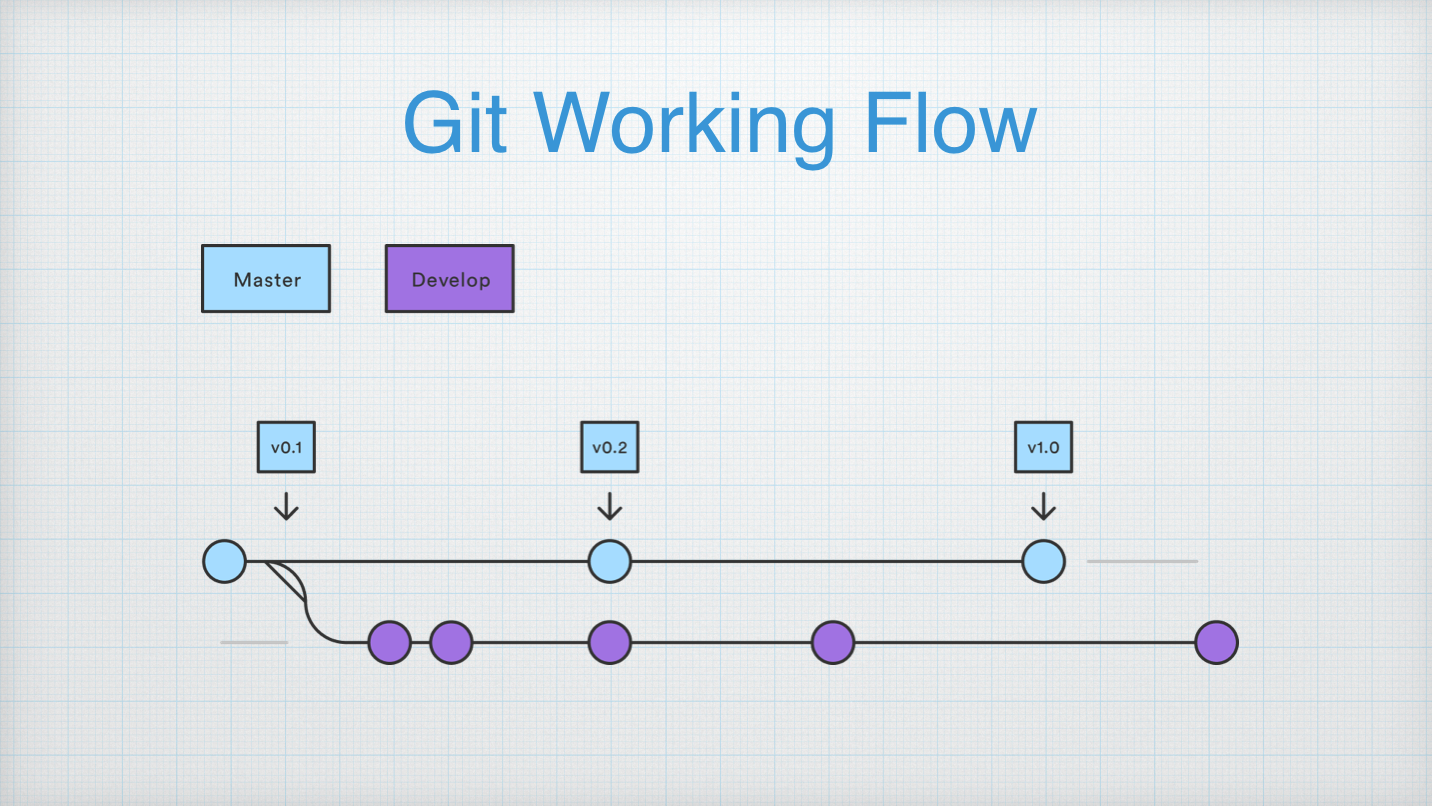
这张图可以简单的看什么是 Git 工作流,有开发分支,有主干分支,主干分支上有一些发布,这是一个比较简略的工作流。
我从协作人员数量和开发周期这两个维度划分四个象限出来,划分了几类比较常见的场景。我将详细说明这四种场景下,如何进行工作流的选择。
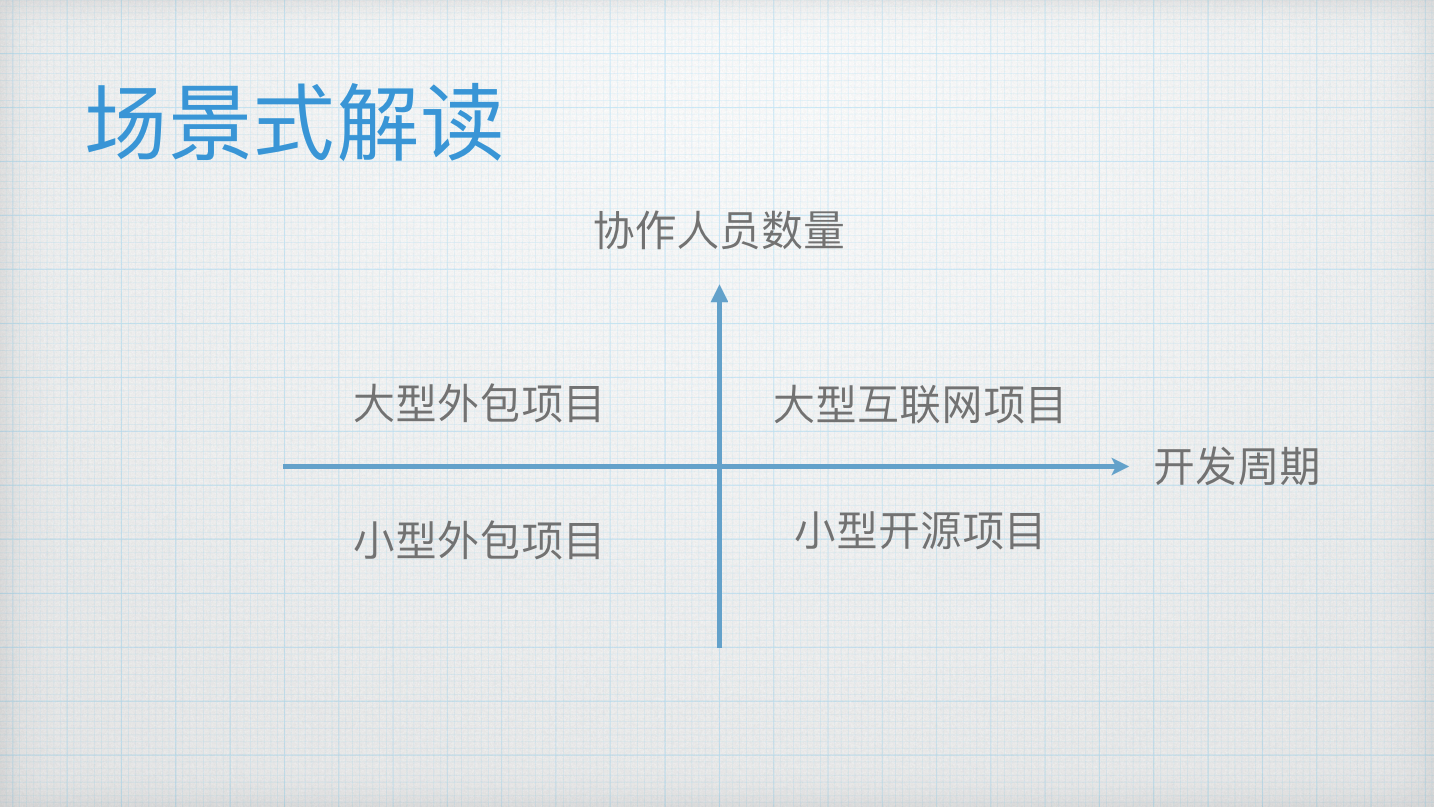
工作人员数量比较少的,开发周期比较短的往往是小型外包项目。比如可能是小型外包公司,三五个人的团队,有前端和后端,项目可能是三个月,更快的是两个月搞定,没有后续维护的压力,这个项目交付之后基本告一段落,我想说的是项目即便不是外包项目,但若符合协作人员数量少,开发的周期短也适合这种工作流。
此外还有协作人员数量多,开发周期比较短。比如一个大型外包项目。项目往往有各种模块系统的集成,整个开发团队达到几十个人的规模,不同的人在为各个模块做开发工作,属于图示中第二种工作场景。
也有些项目,协作人员数量比较少,开发周期比较长。比如开源项目,你开发一个开源软件,定期可能要发布一些版本,偶尔还要接受一些其他人发过来的贡献。
最后一类是最复杂、最麻烦的,但却是很多互联网公司的真实使用场景,维护一整套线上运行的系统,但是这套系统没有开发终点,只是不停的在迭代,整个服务庞大,功能模块众多,开发人员的并行性也比较强。
大致上我认为解决中小型团队工作流的场景就分为这四种,我们来分别阐述一下适合他们的工作流程。
小型外包项目

小型外包项目大家往往都是三五个人在一起工作,沟通成本低,效率高,Code Review 需求不强,很多人说 Code Review 需求强不强不是项目决定的,但是小型外包项目具体的目的是尽快的帮客户把代码交付,即便我极力推荐 Code Review,然而在显示中这个过程事实上在大多数的外包公司并不存在。

小型外包项目的工作流其实非常的简单,一条主干就足够了,三五个人在一条分支上开发,你的代码写完提交上来,别人同步下来然后再提交,当某一个版本合适发布的时候发给客户验证,有问题的话再去修复再发一个版本,非常简单。如果是这种形式的项目,一条分支解决所有问题,不要让复杂的工作流变成你工作的绊脚石。
小型开源项目

小型开源项目往往是由个人或者小团队维护,特点是往往要接受第三方的贡献,Code Review 的需求强烈,在开源社区内 Code Review 是比较重要的过程;还有一个特点是开源项目往往有维护多个版本的需求,与小型外包项目不太一样,小型外包项目你跟客户交付的软件很少有 1.0 继续维护,2.0 继续维护的概念。
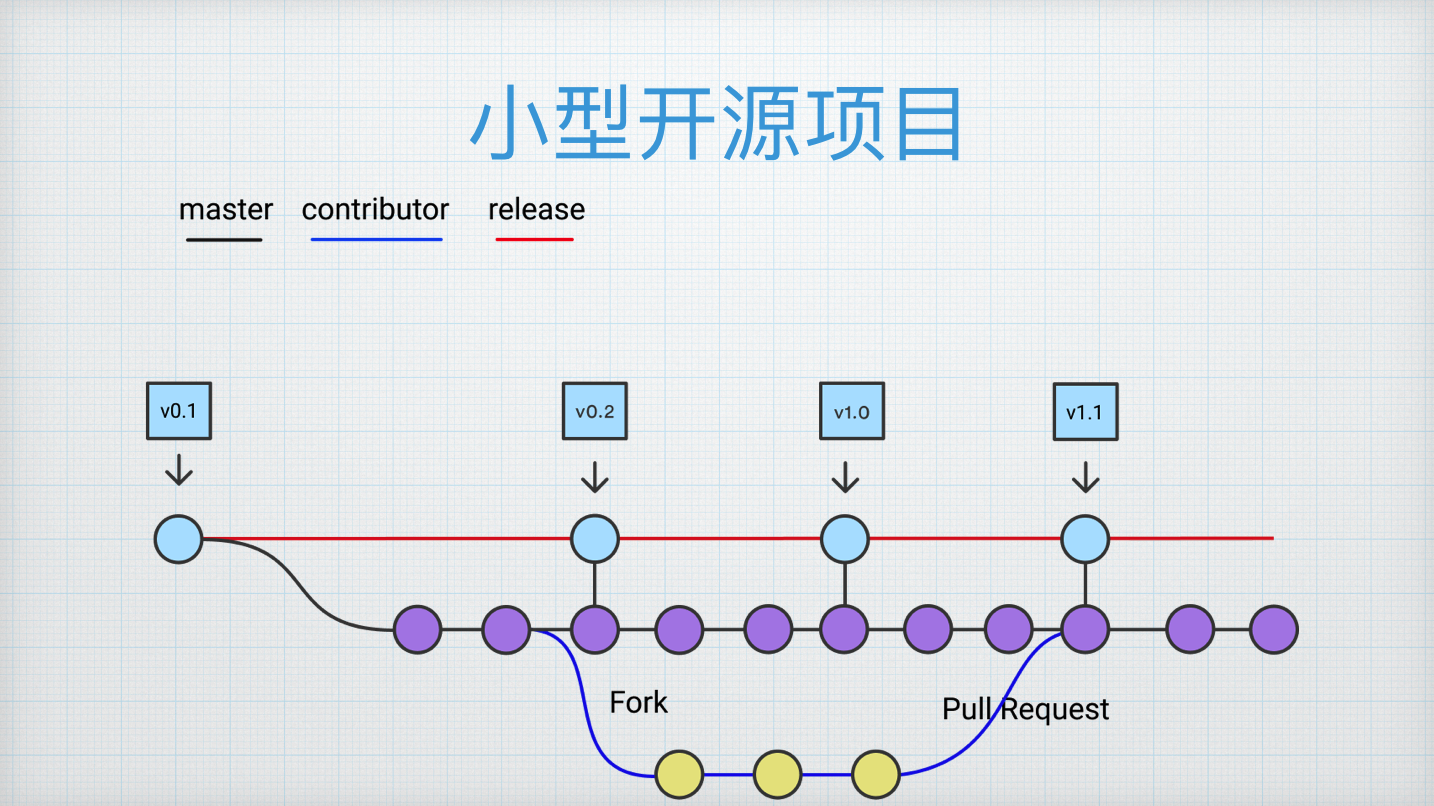
小型开源项目其实它的流程相对也是比较简单,可以看到这边其实有一个分支(红色的线),下面有紫色的点是主的开发分支。主开发分支上往往是 Master,主开发分支上会有很多提交,团队的成员来提交,包括第三方的爱好者看到你的代码觉得不错,从这边 Fork 得到一个自己的项目,做完一些贡献之后提交 Pull Request 到主干分支这里来,在这个过程中可以进行 Code Review,而最终发布的过程是由开源项目的维护者来决定的。开源项目也有可能维护多个版本的情况,维护多个版本就是多条分支线(红色)。
大型外包项目

大型外包项目的特点是开发人员比较多、分模块并行开发,Code Review 的需求强烈,此外需要比较短的时间内把这么大规模的项目做出来,分模块进行开发,并行开发也是必然的。
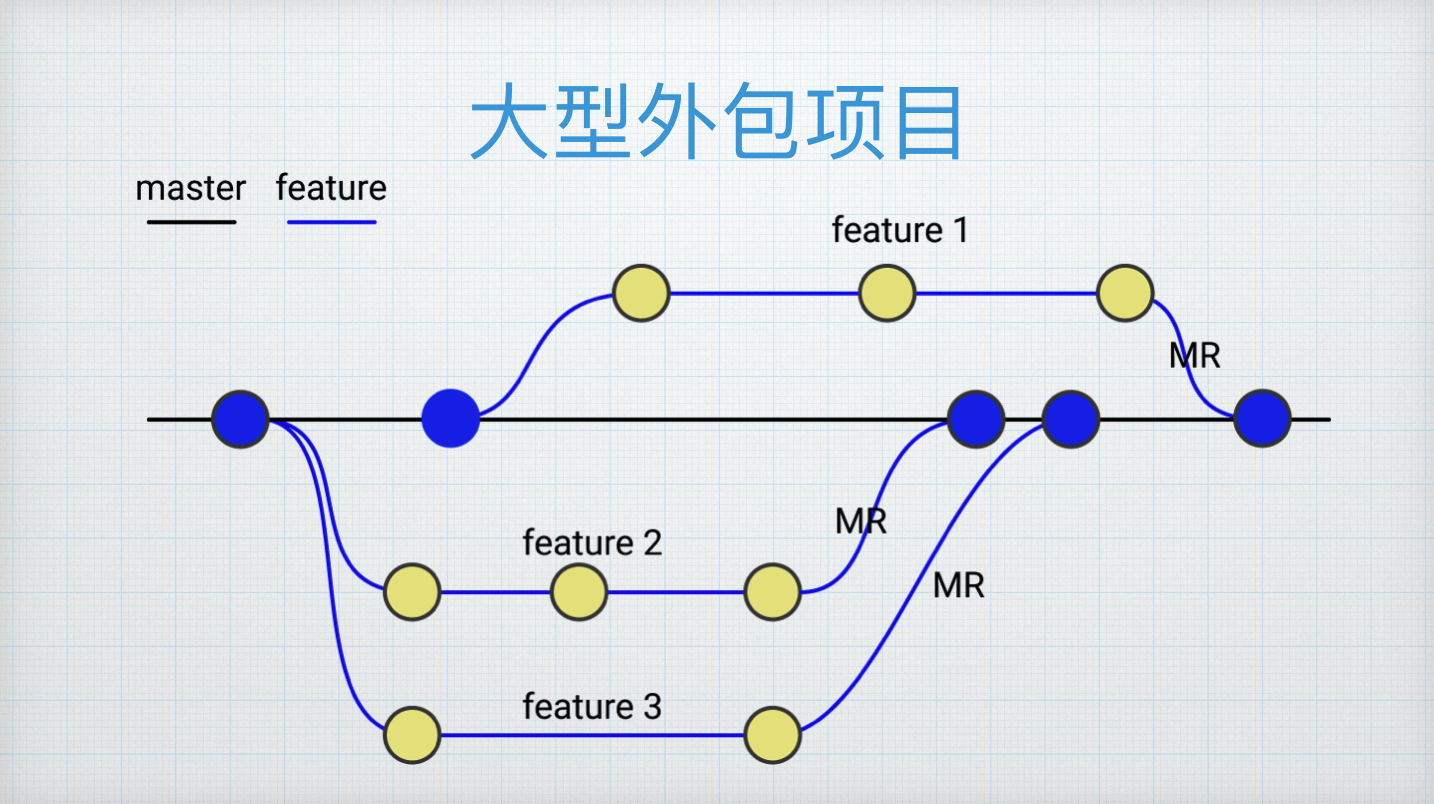
我们看一下大型外包项目比较适合用什么样的形式。
这个工作流从本质上来讲是基于特性分支来做的工作流,大型外包项目往往也没有多个大版本,一般情况下只有一个主版本,这条黑色的线就是主分支,主分支上可能有多个团队,多个团队负责不同的模块开发,某个团队基于主干开一个特性分支,提交完毕之后会发一个 MR 到主干分支来,在这个过程中可以做 Code Review,在这个过程中可以使用 Coding 的工具列出这个分支相对于主干分支的差异,评审通过后就可以合并到主干上去。其他的团队也可能会在不同的 Master 上的节点新建分支来进行开发。
并性开发的情况下,如果两个小组开发的内容是属于同一个模块,他们两个产生冲突的可能性非常大。如果说他们开发的功能是相对独立的,比如说这个是模块A 这个是模块B,这个人专门做账户系统,这边的人做订单的系统,那么他们两个冲突概率比较小。本质上讲,冲突的根本原因在于并行开发同一个文件,跟用什么版本控制工具和用什么分支管理模型都没有关系。并行开发的情况下避免冲突的点不在于一定要把这些分支做成一致,而是尽量的让这些部门和分支上开发的内容在项目层面上拆成不同的模块,通过项目模块划分方式减少冲突。
并行开发这种模型一条主干分支开若干个特性分支,特性分支经过评审合并到主干,主干还是会像小型外包项目一样由项目经理决定什么时间何时发布打个标签交给客户。
大型互联网项目

大型互联网项目是比较麻烦的,往往开发人员多,还会有一些紧急的情况。比如有一天你的用户突然告诉你的网站会泄露密码,我们需要立即快速的做线上修复。这跟传统外包项目不太一样,传统外包项目就算开发过程中已知现在项目的代码有 Bug,但是因为这个版本还没有交付给客户,不用一定要让团队停下工作立即将问题修复之后才能继续。
互联网项目往往 Code Review 的需求强烈,它是从源码的角度上,就是在提交的时候尽可能的避免线上问题的出现性。
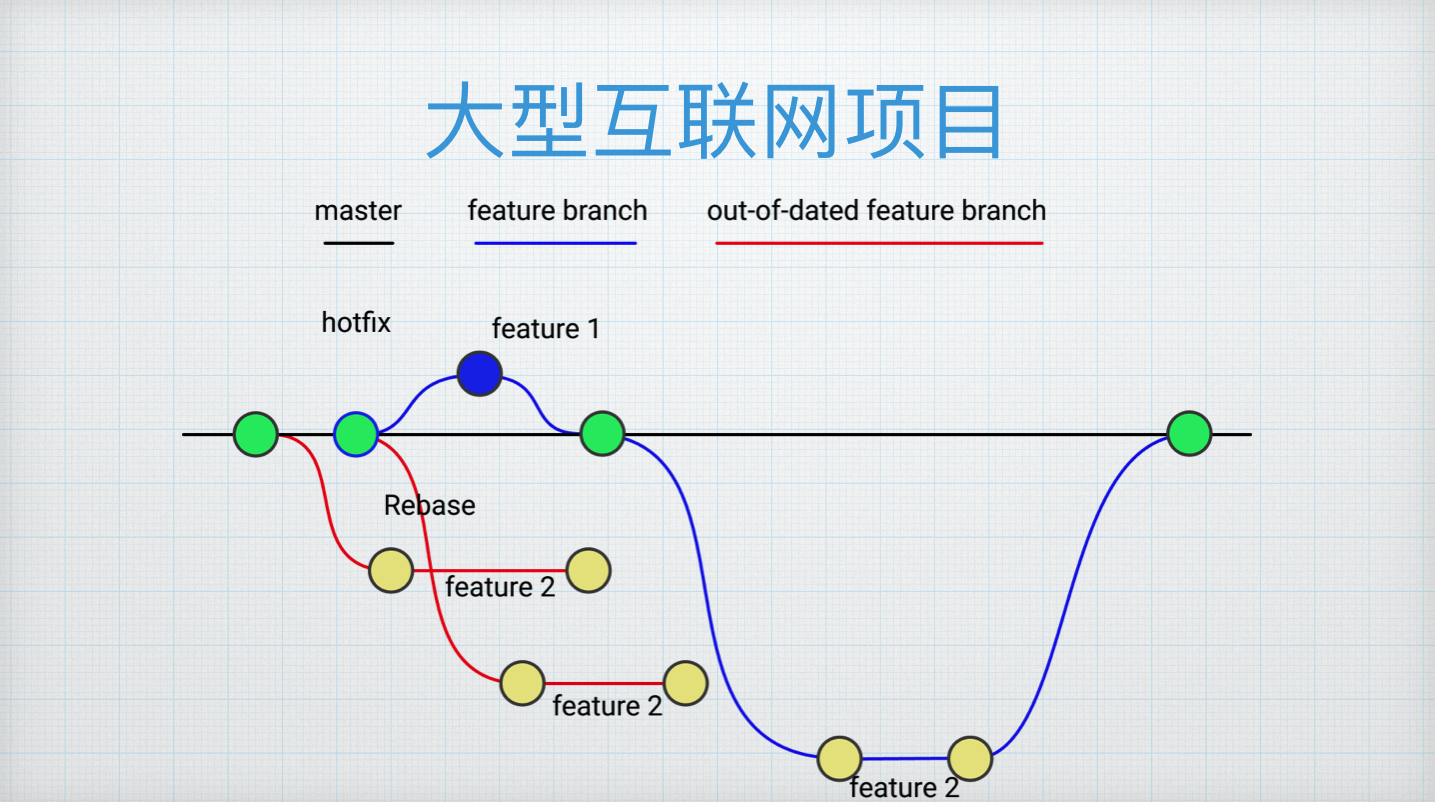
图上黑色的一条线是 Master 分支,主分支上有很多提交的点,某一个团队可能基于某个点上进行开发,像刚才的大型外包公司类似,开一个分支,开发某一个功能,某个功能开发完毕的时候提交到 MR。
但这个过程会被线上出现紧急问题打断,我们需要基于线上的版本立即开一个新的分支,做一个快速的修复再合并到主干分支上去(hotfix)。
主干分支的每一个节点都代表一次线上的成功发布,主干分支最新的点代表现在线上运行的最新的版本。这就带来一个好处:主干分支上的点可以用来作为开发的基准。因为所有开发者都是基于主干分支做开发,这就要求保证主干分支上的代码必须是稳定可靠的,否则容易出现 A 在 B 的不可靠的代码基础上做了开发,如果最终验证 B 的代码有问题,需要回退的时候,往往会牵连到 A 的正常代码,这无疑是一种效率的降低。
而什么样的代码是“稳定可靠的代码”呢?当然大家的评判标准不同:
可能是:高级程序员写的代码
可能是:经过评审的代码
可能是:经过测试的代码
而最可靠的是:经过评审,测试,并最终经过生产环境验证的代码。
从这个角度考虑,我们提高“稳定可靠的代码”的审核标准,让主干分支最新版本始终与线上生产环境运行版本对应就可以避免掉这类的效率降低,同时因为更严苛的代码并入主干的标准使得线上的生产环境极大的减少因为代码 bug 导致的生产事故。
那某个分支基于比较老旧的版本开发,它的功能还没有开发完毕,而线上的版本有其他的团队开发,已经更新上线,导致这个东西落后怎么办呢?有两种办法:一种是 Rebase,Base 就是基准,Rebase 就是变更基准,图示有两个 Feature2,第二个 Feature2 就是 Rebase 之后的。另一种是 Merge ,Merge 是从主干分支往特性分支做合并,跟常规的 Merge Request 是反的,合并之后即可实现同步到所有主干上的代码,就不再落后了。所以两种方式解决你的特性分支落后于主干的情况,具体的情况可能与可根据不同的团队偏好调整。
Git 的工作原理
关于 Git 的原理,很多人听了分支、合并不知道怎么回事,很多人用了很久也不知道 Git 到底怎么存储文件。

这张图里可以看到有一条红色的线,这条红色的线是提交的历史,它对应于每个开发修订版列表,也对应于某一个主干分支。这条线的最新版本是 Master 和 v1.0 所指向的版本,v1.0 是一个标签,Master 是个分支,他们其实都指向一个具体的修订版(绿色的原点),你改一次代码、提交一次会产生一个新的修订版,这些分支会指向不同的修订版,这些指向是会变的。
我们都知道 Git 所管理的是代码库,而代码库就是一个文件夹,文件夹有很多代码和文件夹,文件夹有子文件夹,子文件夹中又有文件,Git 的每一个修订版都会对应一个 Tree,目录里面有很多子目录,子文件。
Git 的原理很简单,每一个修订版对应一个 Tree,每一个 Tree 又包含了所有版本的文件。
小贴士
冲突
我经常会收到一些用户和朋友的疑问,比如出现了冲突报错。冲突是什么呢?该如何解决呢?
先讲如何解决,解决冲突需要你决定这个冲突端内容最终应该是什么样的形式,解决完冲突的这个文件就是是你想要的最终结果,冲突解决是以业务为目的让原文件呈现最终状态的过程。
虽然冲突解决有一套理论,但是我们更希望从最初避免问题。在并行开发中,不同的开发者之间修改了同一个文件和同一个模块,就有可能产生冲突,一个东西被两个人改了,Git 就不知道该怎么处理。所以冲突的避免不是你使用什么流程模型、也不是使用什么代码管理工具解决,而是由你们的工作安排来解决的,避免的方式是让代码的结构划分的更合理,让不同的模块更为独立。
大文件
大型文件往往会严重拖慢 Git 的性能,Git 的性能消耗不光存在于代码托管的服务器端,也体现在用户端。主要影响是计算文件的 sha1 哈希和压缩,大型文件这两个操作都很慢。Git 本质上是用来管理原代码而不是管理大文件的,如果真的是想把大文件存在 Git 中推荐使用 Git LFS。
Git Bisect
都说 Git 是用来存储原代码仓库的可以帮你追溯历史,但很多人不知道该怎么干。例如说忽然出现一个 Bug,查遍所有资料,还是无法定位问题,那如何找到导致问题代码呢?Bisect 会让你快速的找到到底是哪一个提交导致的这个问题,你只需要告诉 Git 到底这个版本是好是坏就可以了。
具体点来讲是开始 Bisect 后,Git 会自动检出一个版本,你告诉他这个版本有没有这个bug,不管有还是没有,Git 都会在最小的可能范围中基于二分查找法给出下一个验证的提交,直至最终找到导致问题的提交。
Git Work-tree
有时候我们需要同时查看一个仓库内不同版本的文件,或者有需要同时编译多个不同版本的源代码。这时候直接使用 git checkout 是很麻烦的,必须不断的把版本来回切换,而使用 work-tree 可以很方便的给一份 git 仓库设置多个检出目录树(工作区)。
希望大家可以根据自己团队的实际情况及使用场景,找到适合自己的工作流。
标签云
-
VirtualminSecureCRTAppleSwiftCactiSupervisorKubernetesOpenStackOpenrestyGolangVagrantVPSWPSVsftpdMariaDBHAproxyCrontabDeepinDockerShellOpenVZ部署MacOSSQLAlchemyPuttyRedisKloxoWordPressSambaBashSVNMongodbPostgreSQLFlutterWiresharkDNS监控RsyncKVMCentosLinuxFlaskRedhat代理服务器ApacheNFSTomcatNginxPHP缓存WindowsTensorFlowIptablesWgetCurlSnmpYumMemcacheOfficeSaltStackPythonIOSCDNPostfixFirewalldGITZabbixKotlinUbuntu集群iPhoneAndroidSystemd备份TcpdumpAnsibleJenkinsVirtualboxLUASocketInnoDBLVMSwarmLighttpdMySQLDebianGoogle容器squidSSH