Tomcat是怎样处理搜索引擎爬虫请求的?
每个置身于互联网中的站点,都需要搜索引擎的收录,以及在适时在结果中的展现,从而将信息提供给用户、读者。而搜索引擎如何才能收录我们的站点呢?
这就涉及到一个「搜索引擎的爬虫」爬取站点内容的过程。只有被搜索引擎爬过并收录的内容才有机会在特定query命中之后在结果中展现。
这些搜索引擎内容的工具,又被称为爬虫、Sprider,Web crawler 等等。我们一方面欢迎其访问站点以便收录内容,一方面又因其对于正常服务的影响头疼。毕竟 Spider 也是要占用服务器资源的, Spider 太多太频繁的资源占用,正常用户请求处理就会受到影响。所以一些站点干脆直接为搜索引擎提供了单独的服务供其访问,其他正常的用户请求走另外的服务器。
说到这里需要提一下,对于是否是 Spider 的请求识别,是通过HTTP 请求头中的User-Agent 字段来判断的,每个搜索引擎有自己的独立标识。而且通过这些内容,管理员也可以在访问日志中了解搜索引擎爬过哪些内容。
此外,在对搜索引擎的「爬取声明文件」robots.txt中,也会有类似的User-agent 描述。比如下面是taobao 的robots.txt描述
User-agent: Baiduspider
Allow: /article
Allow: /oshtml
Disallow: /product/
Disallow: /
User-Agent: Googlebot
Allow: /article
Allow: /oshtml
Allow: /product
Allow: /spu
Allow: /dianpu
Allow: /oversea
Allow: /list
Disallow: /
User-agent: Bingbot
Allow: /article
Allow: /oshtml
Allow: /product
Allow: /spu
Allow: /dianpu
Allow: /oversea
Allow: /list
Disallow: /
User-Agent: 360Spider
Allow: /article
Allow: /oshtml
Disallow: /
User-Agent: Yisouspider
Allow: /article
Allow: /oshtml
Disallow: /
User-Agent: Sogouspider
Allow: /article
Allow: /oshtml
Allow: /product
Disallow: /
User-Agent: Yahoo! Slurp
Allow: /product
Allow: /spu
Allow: /dianpu
Allow: /oversea
Allow: /list
Disallow: /
我们再来看 Tomcat对于搜索引擎的请求做了什么特殊处理呢?
对于请求涉及到 Session,我们知道通过 Session,我们在服务端得以识别一个具体的用户。那 Spider 的大量请求到达后,如果访问频繁同时请求量大时,就需要创建巨大量的 Session,需要占用和消耗很多内存,这无形中占用了正常用户处理的资源。
为此, Tomcat 提供了一个 「Valve」,用于对 Spider 的请求做一些处理。
首先识别 Spider 请求,对于 Spider 请求,使其使用相同的 SessionId继续后面的请求流程,从而避免创建大量的 Session 数据。
这里需要注意,即使Spider显式的传了一个 sessionId过来,也会弃用,而是根据client Ip 来进行判断,即对于 相同的 Spider 只提供一个Session。
我们来看代码:
// If the incoming request has a valid session ID, no action is required
if (request.getSession(false) == null) {
// Is this a crawler - check the UA headers
Enumeration<String> uaHeaders = request.getHeaders("user-agent");
String uaHeader = null;
if (uaHeaders.hasMoreElements()) {
uaHeader = uaHeaders.nextElement();
}
// If more than one UA header - assume not a bot
if (uaHeader != null && !uaHeaders.hasMoreElements()) {
if (uaPattern.matcher(uaHeader).matches()) {
isBot = true;
if (log.isDebugEnabled()) {
log.debug(request.hashCode() +
": Bot found.: New bot session.: Bot session accessed..*[bB]ot.*|.*Yahoo! Slurp.*|.*Feedfetcher-Google.*";
// 初始化Valve的时候进行compile
uaPattern = Pattern.compile(crawlerUserAgents);
这样当 Spider 到达的时候就能通过 User-agent识别出来并进行特别处理从而减小受其影响。
这个 Valve的名字是:「CrawlerSessionManagerValve」,好名字一眼就能看出来作用。
其他还有问题么?我们看看,通过ClientIp来判断进行Session共用。
最近 Tomcat 做了个bug fix,原因是这种通过ClientIp的判断方式,当 Valve 配置在Engine下层,给多个Host 共用时,只能有一个Host生效。 fix之后,对于请求除ClientIp外,还有Host和 Context的限制,这些元素共同组成了 client标识,就能更大程度上共用Session。
修改内容如下:
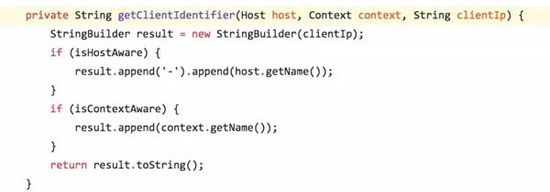
总结下, 该Valve 通过标识识别出 Spider 请求后,给其分配一个固定的Session,从而避免大量的Session创建导致我资源占用。
默认该Valve未开启,需要在 server.xml中 增加配置开启。另外我们看上面提供的 正则 pattern,和taobao 的robots.txt对比下,你会出现并没有包含国内的这些搜索引擎的处理,这个时候怎么办呢?
在配置的时候传一下进来就OK啦,这是个public 的属性
public void setCrawlerUserAgents(String crawlerUserAgents) {
this.crawlerUserAgents = crawlerUserAgents;
if (crawlerUserAgents == null || crawlerUserAgents.length() == 0) {
uaPattern = null;
} else {
uaPattern = Pattern.compile(crawlerUserAgents);
}
}
标签云
-
SnmpsquidZabbix部署DeepinLighttpdOpenrestyOpenStackGoogle集群Centos监控VirtualminCDNMemcacheOfficeWiresharkIOSCurlYumIptablesRsyncVsftpdPHPMariaDBHAproxyFlutterFirewalld缓存TomcatUbuntuAnsibleJenkinsKubernetesSwarmGolangFlaskGITWPSKVM备份PythonBashPostfixSupervisorVirtualboxRedisKotlinNFSSwiftSVNVPSShellVagrantPostgreSQLPuttyAppleDNSAndroidWordPressDockerCrontabNginxLVMRedhatMongodbWgetLinuxSQLAlchemyKloxoMySQLSecureCRTDebianSocketInnoDBMacOSiPhoneSSHWindowsLUA容器SystemdTensorFlow代理服务器SaltStackCactiOpenVZTcpdumpSambaApache