Mysql的InnoDB引擎的数据结构(B+树)以及聚簇索引的介绍
前言:自己的对知识的复习和归纳,参考网上资料和书籍(Mysql高性能),部分概念便于理解会做简单处理。
数据库中使用什么数据结构作为索引呢?
- 数组:如果是二分查询,查询时间OK,但是插入、更新慢。
- 链表、环形链表:查询慢。
- 跳表:作为索引,思想是ok的,但是不贴合磁盘特性。
- hash : 虽然可以快速定位,但是没有顺序,不支持区间查询。
- 树结构:B+的设计,very good。
数据库的需求?
比较常见的查找需求:
- 根据某个值查找数据,比如 select * from user where id=12;
- 根据区间值来查找某些数据,比如 select * from where id > 20;
假设是树结构呢,有什么问题?
我们来看下最简单的二叉树(以下提到的二叉树都指平衡二叉树)
那如果采用最简单的二叉树(平衡二叉树)作为数据库的索引存储,有什么问题呢?
首先,索引是存储存在在硬盘的。
(比如:给某张表,1亿的数据记录建立二叉查找树索引,索引中大概会有一亿的节点,假设每个节点占用16字节,大约需要1GB)
1.不支持区间查找 — > 非叶子节点不存储数据,只做索引(叶子节点的索引),然后把叶子节点连接起来,就可以支持区间查找。
2.速度慢(把数据存储在硬盘,每个节点的读取或者访问,都对应一次磁盘IO操作(ms级别),数的高度就对应每次查询的IO次数。) — > 降低树的高度,M叉树。
如果M位100, 100叉树,一亿的索引节点,树的高度为3,所以最多3次磁盘IO操作就能获取到数据。
所以,索引的查找从磁盘IO读取变成内存查找。
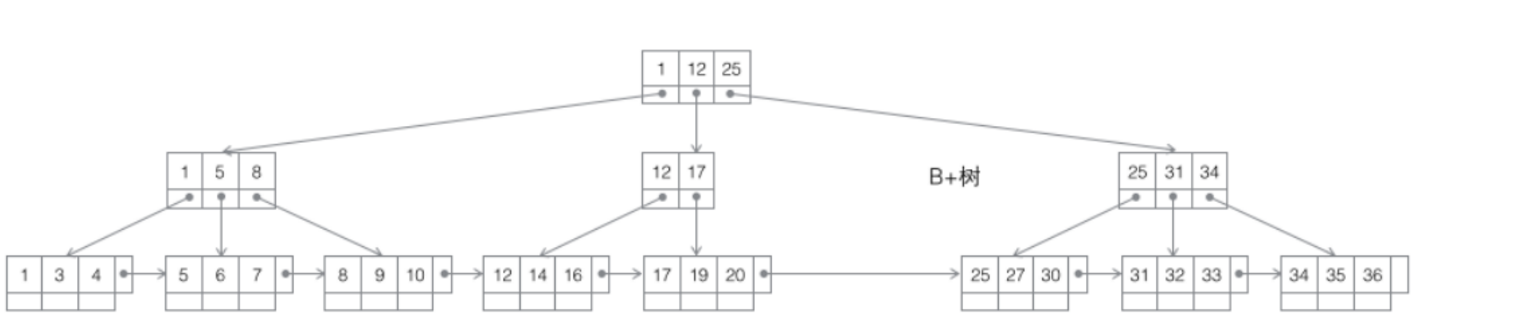
这就是B+树(有序数组链表+平衡多叉树)
什么是B树(多路平衡查找树):
只是一个每个节点的子节点个数不能小于 m/2 的m叉树 –> 有序数组 + 平衡多叉树

B+树、磁盘 == 非常快的查找速度(索引):
- 程序的访问局部性:当一个数据被用到时,其附近的数据也通常会马上被使用。
- 时间局部性:被使用的数据,未来很大概率会被再次使用。
- 空间局部性: 被使用的数据,其附近的数据,大概率会被使用。
- 磁盘的预读取:磁盘是按页(简单理解为4KB)读取。 — > 如果是B+树,让一个节点的大小 == 一个磁盘页,一次磁盘IO读取就是一个节点,而B+树中,一个节点内的数据是连续的,所以能充分利用程序的访问局部性原理。(索引可以将随机I/O变为顺序I/O。)
比较:二叉树 — >如果索引数据大,树高度深,相邻数据的节点在物理位置距离远,每次预读取的数据基本基本不会被用到。
那我们来看下磁盘是怎么读取数据的?
先看下磁盘结构:
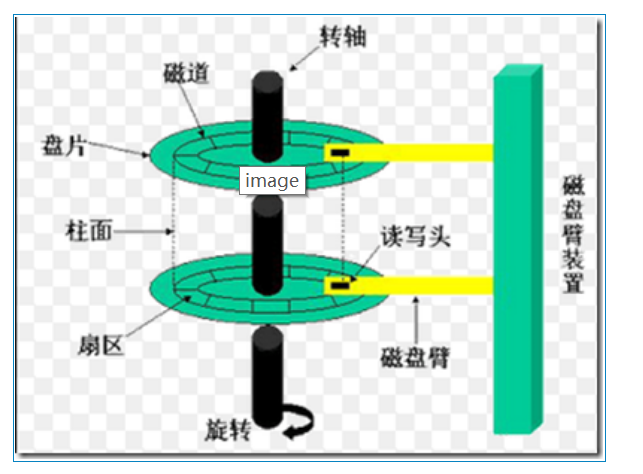
磁盘的读写:读写主要是通过传动手臂上的读写磁头来完成。实际运行时,主轴让磁盘盘片转动,然后传动手臂可伸展让读写磁头在盘片上进行读写操作。
扩展:磁盘顺序读取的效率很高。合理利用,顺序读取的速度甚至比内存高(kafka、rocketMq等中间件,就是利用磁盘的顺序读取,来实现高性能)。
聚簇索引和非聚簇索引
聚簇索引和非聚簇索引概念
- 聚簇索引的叶子节点就是数据节点
聚簇的意思:数据行被按照一定顺序一个个紧密地排列在一起存储。(索引是有序的)
InnoDB : 主键索引和数据文件简单理解为同一份文件
- 非聚簇索引的叶子节点仍然是索引节点,只不过有指向对应数据块的指针
从MYISAM存储的物理文件我们能看出,MYISAM引擎的索引文件(.MYI)和数据文件(.MYD)是相互独立的。
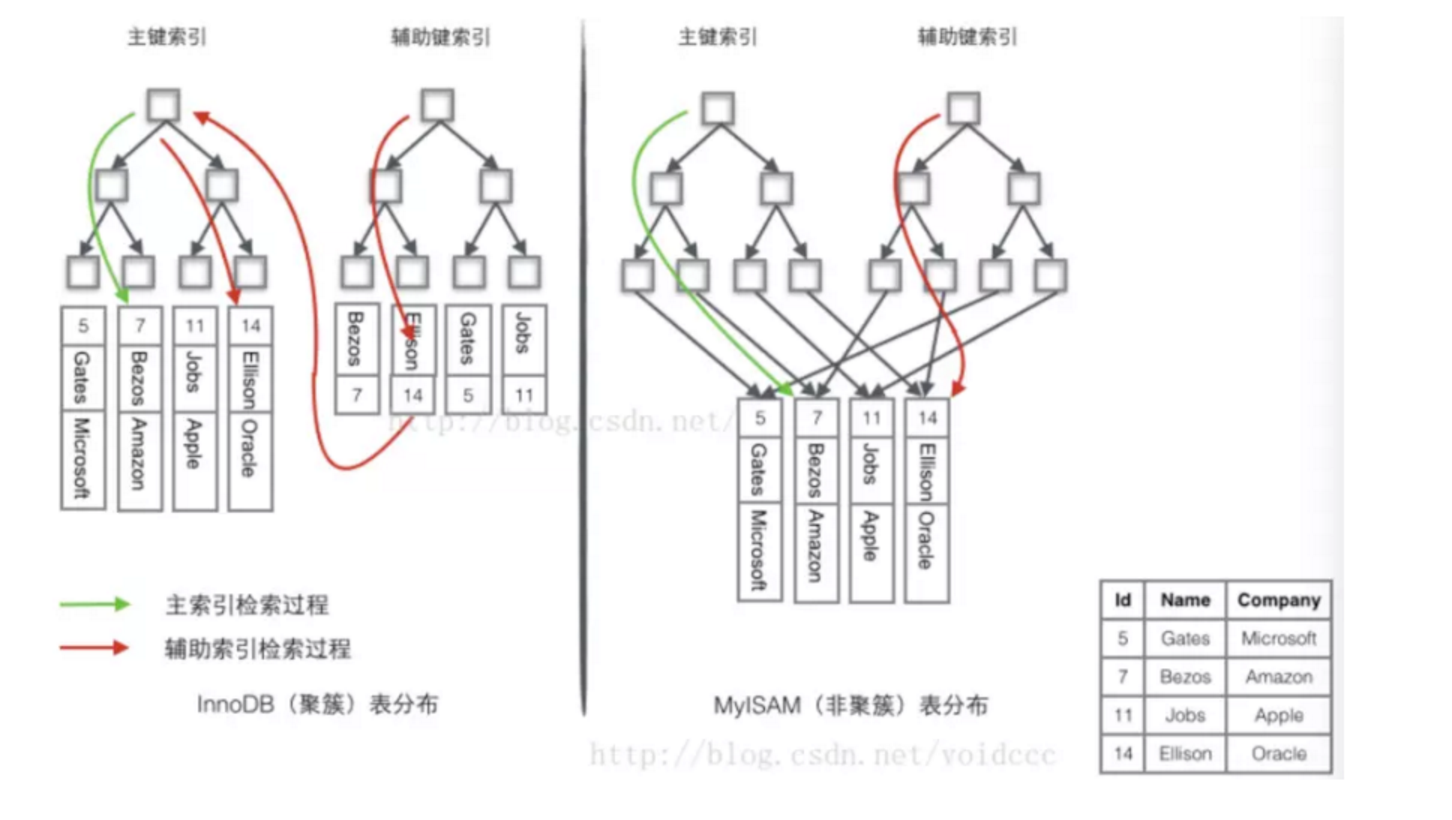
聚簇索引的优点和缺点
- 优点
- 1.查询通过聚簇索引可以直接获取数据,相比非聚簇索引需要第二次查询(非覆盖索引的情况下)效率要高。
- 2.聚簇索引对于范围查询的效率很高,因为其数据是按照大小排列的。(磁盘顺序读取)
- 缺点
- 1.索引的更新代价高:数据更新,为了保持聚簇索引的有序,需要将数据移动到相应的位置,而且可能导致页分裂(页已满)。
- 2.插入的速度严重依赖插入的顺序,如果是按照主键索引的速度插入,非常快,非主键索引的插入,慢。
- 3.二级索引访问需要两次索引查找,而不是一次。
- 4.聚簇索引可能导致全表扫描变慢,尤其是行比较稀疏,或者由于页分裂导致数据存储不连续的时候。(未get到)
扩展:
InnoDB的插入:
首先,操作系统写磁盘是定期flush将缓存刷到磁盘。
多条记录如果是按照主键索引的顺序插入:
- 插入的数据很大概率在同一个磁盘页,并且以及加载到内存中,按多条记录按主键索引顺序的插入,可能简单理解为在一个节点的内存中,插入多条数据,然后一次性flush到磁盘。
多条记录的非主键索引的插入:
- 数据很大概率不在同一个磁盘页或者(或者目标页已经从缓存刷到磁盘),所以可能需要多次IO操作,增加来很多开销。
- 频繁的移动、分页操作造成了大量的碎片,得到了不够紧凑的索引结构,后续不得不通过OPTIMIZE TABLE来重建表并优化填充页面。
基础知识
1亿 = 100000000
1G等于1024M,1M等于1024KB,1KB等于1024B,1B等于8位(bit)
1秒=1000毫秒(ms), 1秒=1000000微妙(μs), 1秒=1000000000纳秒(ns)

简单总结:
寄存区 = 1ns
CPU缓存的读取的速度 == 1 – 10ns
内存的读取速度 = 100 -150ns
硬盘 = 3 – 15ms
网络去读 = 10ms
所以,简单理解为 硬盘差内存的1w倍, 内存差CPU缓存100 倍,CPU缓存差寄存器10倍;
标签云
-
DeepinBashWordPressAnsibleVirtualboxFirewalldKloxoKVMCentosCDNAppleLUALighttpdVirtualminWindowsCrontabWgetAndroidPythonMySQLSupervisor集群ShellDNSVagrantHAproxyNginxZabbixSSHInnoDBSVNDebianMariaDBTensorFlowApacheFlutterVPS备份GolangOpenresty容器WiresharkGoogleMemcacheIOSMacOSOfficeRedhatPHP缓存部署TcpdumpSaltStackGITOpenStackJenkinsRsyncFlaskMongodbSocket代理服务器iPhoneTomcatWPSSambaIptablesKubernetesLinuxPostgreSQLOpenVZDockerSQLAlchemyLVMSwarmSnmpSystemdCactiPuttyPostfixRedisNFS监控SwiftCurlUbuntusquidKotlinYumVsftpdSecureCRT