linux中awk工具的使用
add by zhj: awk很强大,它是一个简单的编程语言,国外有本专门的书介绍它的用法。《effective awk programming》,它支持整型,字符串型,数组,变量在使用前不需要
定义,直接使用,因为每种数据类型都有默认的初始值。它还支持if/for等逻辑语句
原文:https://blog.51cto.com/13866901/2166164?tdsourcetag=s_pctim_aiomsg
运行环境:centos6 Vmware
一、awk简介
awk是一个非常好用的数据处理工具,相对于sed常常作用于一整个行的处理,awk则比较倾向于一行当中分成数个【字段】处理,因此,awk相当适合处理小型的数据数据处理。awk是一种报表生成器,就是对文件进行格式化处理的,这里的格式化不是文件系统的格式化,而是对文件内容进行各种“排版”,进而格式化显示;在linux中我们使用的是GNU awk简称gawk,并且gawk其实就是awk的链接文件,因此在系统上使用awk和gawk是一样的。
二、awk的基本用法
awk [OPTIONS] 'program' FILE1 FILE2
- program:PATTERN{ACTION STATEMENT}
- program:编程语言 PATTERN:模式 ACTIONSTATEMENT:动作语句,可以是多个语句,但多个语句中间要使用分号分隔
- OPTIONS:-F[] 指明输入字段分割符 ; -v VALUE 变量赋值;
举例说明:
<code>cat /etc/passwd</code>

<code>cat ceshi.txt |awk -v FS: '{print $1,$3}'(每行按冒号分割,输出第一个域和第三个域;默认为空格分割;注意:awk后续动作都要以单引号引起来)</code>
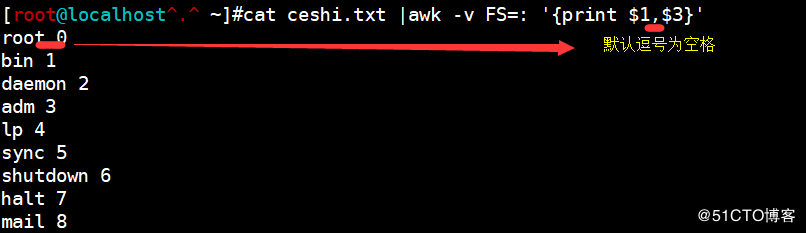
<code>cat ceshi.txt |awk -v FS: '{print $1"XXXX"$3}'("XXXX"代表任意内容,必须用双引号引起来)</code>
三、变量
1、内建变量
- FS 输入字段分隔符,默认为空白
- RS 输入的记录分隔符,默认为换行符
- OFS 输出字段分割符,默认为空白字符
- OFS 输出字段分隔符,默的认为换行符
- NF 当前行的字段的数量
- print NF 显示当前行的字段数
- print $NF 显示当前行的第NF字段的值
- NR 记录号
- FNR 个文件分别计数,显示行号
- FILENAME 当前文件名
- ARGC 命令行参数的个数
- ARGV 保存命令行所给定的各参数的数组
2、自定义变量
(1)-v VALUE (变量名称区分大小写)在这里文件ceshi.txt中有多少行就显示多少行变量的值
<code>awk -v fan="cool" '{print fan}' ceshi.txt</code>

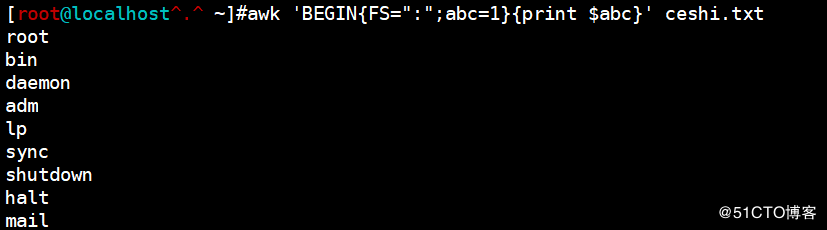
(2)在program中自定义变量
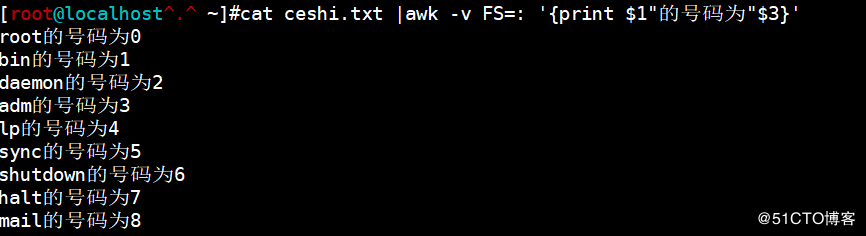
<code>awk 'BEGIN{FS=":";abc=1}{print $abc}' ceshi.txt</code>
四、awk的格式化输出
语法 printf FORNAT,item1,item2
- FORMAT必须提供
- 与print语句不同,printf不会自动换行,需要使用换行符\n
- FORMAT中需要分别为后面的每个item指定一个格式符,否则item无法显示;
格式符介绍:
- %c 显示字符的ASCII码
- %d ,%i 显示为十进制整数
- %e,%E 科学技术法显示数值
- %f 显示为浮点数
- %g,%G 以科学技术法或浮点数格式显示数值
- %s 显示为字符串
- %u 显示无符号整数
- %% 当需要显示%号时需要连续打两个百分号
举例说明:
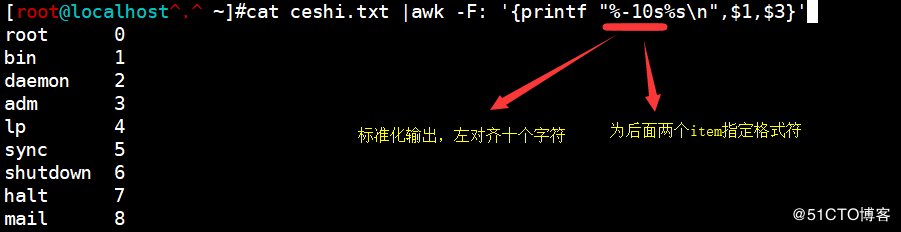
<code>cat ceshi.txt |awk -F: '{printf "%-10s%s\n",$1,$3}'</code>
五、awk的操作符
- 算术操作符 如:A+B A-B A*B A/B
- 字符操作符 字符串链接
- 赋值操作符 如:== += /= %=
- 比较操作符 如:> >= < <=
- 模式匹配操作符 ~ 是否能由右侧指定的模式所匹配 !~是否不能由右侧指定的模式所匹配
- 逻辑操作符 && 与运算 || 或运算
- 条件表达式 selector?if-true-expression:if-ials-expreion
- 函数调用 调用函数来进行数据的处理
举例说明
通过df命令查看当前系统磁盘占用率,查出占用率大于等于百分之20的磁盘名称以及磁盘占用率
<code>df|awk -v FS=% '$0 ~ "/dev/sd" {print $1}'|awk '$NF>=20 {printf "DevName:%-10s Used:%s%%\n",$1,$5}'</code>

<code>awk -v FS=: '{$3>=5?usertype="Big User":usertype="Small User";printf "UserName:%-15s Type:%s\n",$1,usertype}' ceshi.txt</code>

六、awk的控制语句
- if(condition){statements}[else {statement}]
<code>awk -F: '{if($3>=5){printf "%-10s%s\n",$1,$3}}' ceshi.txt</code>

- while循环 while(condition){statements}
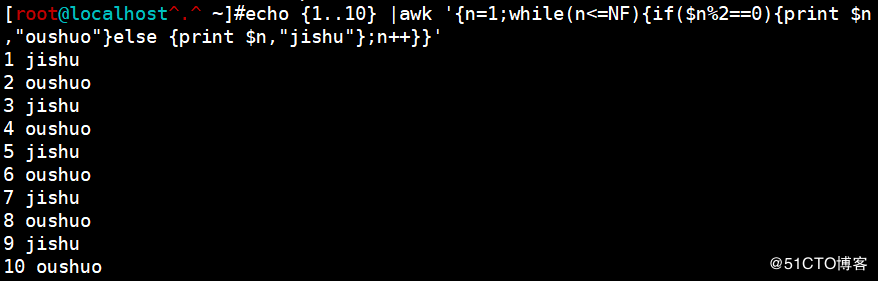
<code>echo {1..10} |awk '{n=1;while(n$n%2==0){print $n,"oushuo"}else {print $n,"jishu"};n++}}'</code>
- do-while循环
- for循环
<code>awk BEGIN'{for(i=1;i</code>

- break
- continue
- delete array
- exit
- next 提前结束对本行文本的处理,而提前进入下一行的处理操作
<code>awk -F: '{if($3%2==0)next;print $1,$3}' ceshi.txt</code>
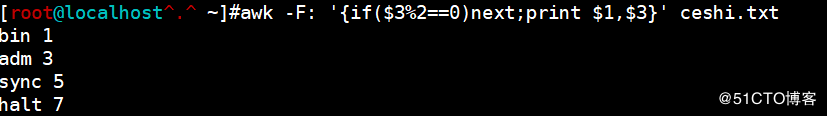
七、awk的性能测试
实验:从1加到100等于多少?
(1)time seq -s "+" 5000000 |bc

(2)time awk BEGIN'{for(i=1;i<=1000000;i++){sum+=i};print sum}'

(3)time awk BEGIN'{i=1;while(i<=1000000){sum+=i;i++};print sum}'

(4)time for ((i=1;i<=1000000;i++));do let sum+=i; done;echo $sum

八、awk数组
数组是一个包含一系列元素的表
格式如下:
abc[1]="libai"
abc[2]="lihei"
abc为数组名,[1][2]为数组下标,可以认为是数组的第一个元素,第二个元素,”libai””lihei”是元素的内容
举例说明:
<code>awk 'BEGIN{fan[0]="libai";fan[1]="lihei";print fan[0]}'</code>
<code>awk 'BEGIN{fan[0]="libai";fan[1]="lihei";print fan[1]}'</code>

<code>awk 'BEGIN{fan[0]="libai";fan[1]="lihei";for (i in fan)print i}'</code>

<code>awk -F: '{{fan[NR]=$1;}{print NR,fan[NR]}}' ceshi.txt</code>

利用数组统计每个ip地址访问量(编辑一个文件,该文件存储ip地址)
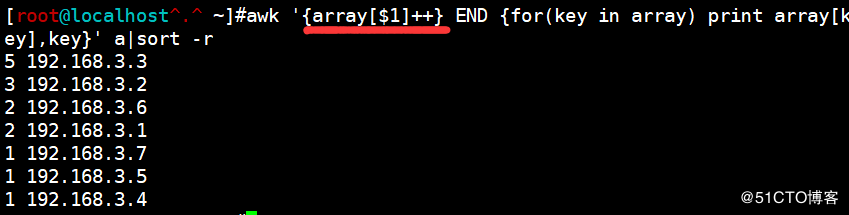
<code>awk '{array[$1]++} END {for(key in array) print array[key],key}' a|sort -r</code>
关于array[$1]++
(1)awk在读取第一行的时候,会读取这个数组,此时的数组是这样的,array[“第一行的内容”]++
(2)此时该数组的值还没有定义,但后面有运算符号++,所以awk会将数字0自动赋值给array[“第一行的值”]做++运算,所以得到的值为1.
(3)在读到与array[“第一行的内容”]相同的时候继续++运算,也就意味着,运算了多少次,就是出现了多少次。
九、awk函数
1、内键函数
(1)数值处理 rand() 返回0至1之间的一个随机数
<code>awk 'BEGIN{print rand()}'</code>

从这张图中我们发现了一个问题,通过使用rand函数生成随机数,但是rand函数返回的值一直不变,所以我们需要配合srand函数
<code>awk 'BEGIN{srand();print rand()}'</code>
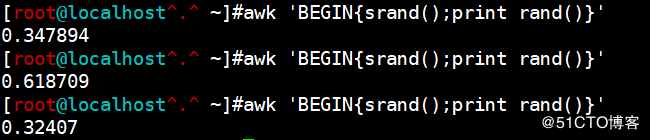
从这张图中我们发现生成的随机数产生了变化,但生成的随机数都是小于1的小数,如果我们想要生成整数随机数,我们可以利用int整数函数截取整数部分的值
<code>awk 'BEGIN{srand();print 100*rand()}'</code>
<code>awk 'BEGIN{srand();print int(100*rand())}'</code>

(2)字符串函数
length([s]) 返回指定的字符串的长度
举例说明
<code>awk '{print $0 length()}' abc.txt (每一行全部字符长度)</code>
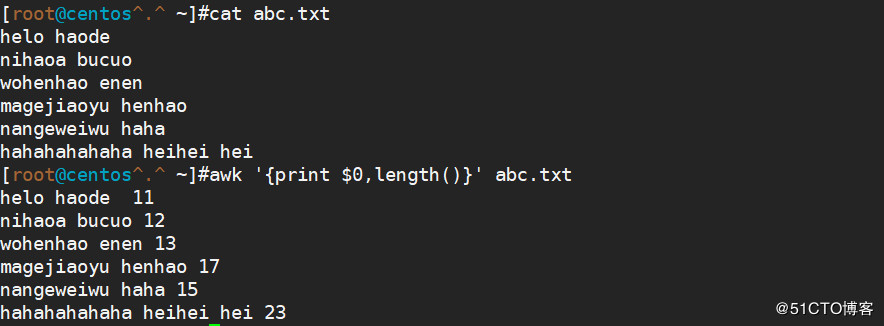
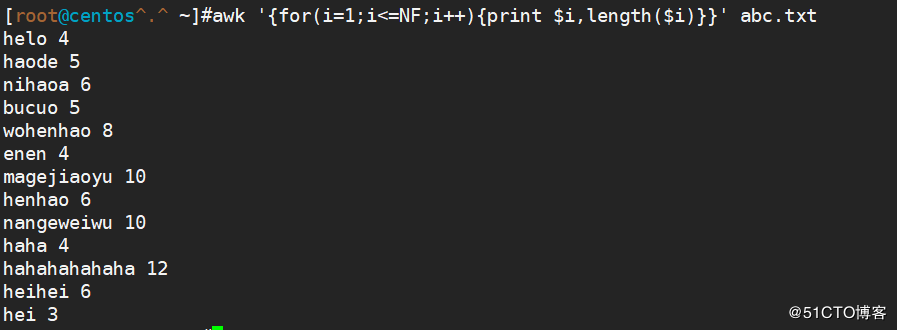
<code>awk '{for(i=1;i$i,length($i)}}' abc.txt(指定字符长度)</code>
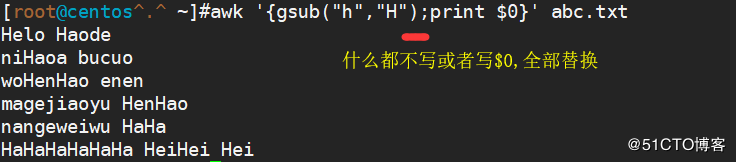
gsub(r,s[,t])基于r所表示的模式来匹配字符串t中的内容,将其所有被匹配到的内容均替换为s所表示的字符串
举例说明
<code>awk '{gsub("h","H",$1);print $0}' abc.txt</code>

<code>awk '{gsub("h","H",$0);print $0}' abc.txt</code>
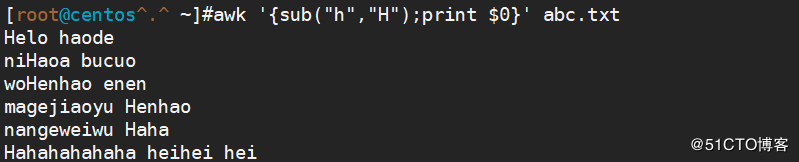
sub(r,s[,t]) 基于r所表示的模式来匹配字符串t中的内容,将其第一次被匹配到的内容替换为s所表示的字符串
举例说明
<code>awk '{sub("h","H");print $0}' abc.txt(只替换指定范围第一次匹配到的符合条件的字符)</code>
split(s,a[,r]) 以r为分隔符去切割字符串s,并将切割后的结果保存至a表示的数组中
举例说明
<code>awk -v aa="李大;李二;李三" 'BEGIN{split(aa,lishijiazu,";");for(i in lishijiazu){print lishijiazu[i]}}'</code>

<code>awk -v aa="cc;ff;dd;ee" 'BEGIN{split(aa,lishijiazu,";");for(i in lishijiazu){print lishijiazu[i]}}'</code>

从上图中我们发现数组元素输出顺序可能与字符串中字符的顺序不同,我们可以采用下面的办法
<code>awk -v aa="cc;ff;dd;ee" 'BEGIN{ abc=split(aa,lishijiazu,";");for(i=1;i</code>

2、用户自定义函数
函数是程序的基本组成部分,awk允许我们定义自己的函数,一个大的程序可以分为多个函数并且每个函数可以独立测试
用户自定义函数的一般格式为:
<code><span>function function_name<span>(argument1,argument2,<span>...<span>)
<span>{
<span>function body
<span>}</span></span></span></span></span></span></span></code>
function_name是用户定义函数的名称,函数名称应以字符的字母并且其余部分可以是数字,字母或下划线的任意组合,awk的保留字不能用作函数名字;函数可以接受以逗号分隔的多个参数,参数不是强制性的,我们也可以创建一个用户定义的函数不带任何参数;函数体由一个或多个awk语句组成。
标签云
-
VPSKVMDNSSnmpSystemdHAproxyGolangLUA部署备份WiresharkVagrantKubernetes容器代理服务器MongodbSVNVirtualminKotlinNFSZabbixBashIptablesJenkinsMariaDBSwiftSSHFirewalldGoogleApple集群LVMDeepinMemcacheSambaOfficeCurlKloxoSupervisorFlutter缓存UbuntuMySQLTomcatPostfixPutty监控PHPSQLAlchemyVsftpdMacOSWordPressOpenVZRedhatNginxAnsibleiPhoneVirtualboxGITCrontabLinuxFlaskLighttpdYumOpenStackDebianSocketPythonTensorFlowRedisInnoDBIOSSwarmSecureCRTAndroidDockerShellSaltStackCactiCDNWPSOpenrestyTcpdumpApacheWindowsCentosRsyncPostgreSQLsquidWget